
Arxiv: COMBO
COMBO使用离线数据集和在模型下进行的 模拟生成的数据同时训练值函数,并额外对通过模型模拟生成的超出支持 范围的状态-动作元组进行值函数的正则化。这导致了超出支持范围的状态动作元组的值函数的保守估计,而无需显式的不确定性估计。
Our goal is to develop a model-based offline RL algorithm that enables optimizing a lower bound on the policy performance, but without requiring uncertainty quantification. We achieve this by extending conservative Q-learning, which does not require explicit uncertainty quantification, into the model-based setting.
我们的目标是开发一种基于模型的离线RL算法,该算法能够优化策略性能的下限,但不需要不确定性量化。我们通过将不需要明确的不确定性量化的CQL扩展到基于模型的设置中来实现这一点。
| Symbol | Meaning |
|---|---|
| 占用量度 | |
| f −interpolation,f是从离线数据集中抽取的数据点的比例 |

-
集成模型
-
初始化经验回放池
-
训练
-
用学习的模型进行分支推演
-
用 的数据,进行保守策略评估。
为了获得对 的保守估计, 我们需要惩罚在可能超出数据集支持范围的上评估的Q值,同时提升可信的状态动作对下的Q值,通过重复以下递归实现:
是离线数据集和模型推演之间的 f −插值,是从离线数据集中抽取的数据点的比例,μ(·|s) 是模型使用的推演分布,可以建模为策略或均匀分布。
在这些 和 的作用下,我们降低了(或保守地估计)模型推演范围内的 Q-值,并提高了离线数据集支持范围上的 Q-值。
这个方法学习自CQL,但是与 CQL 和其他无模型算法相比,COMBO 在学习 Q-函数时学习了比离线数据集中的状态更丰富的状态集。这是通过由学习的动力学模型[ ]推演并经验回放来实现的。
-
使用保守Critic的策略提升
在获得Q函数的估计值 后,策略的更新方式如下:
因为我们使用神经网络对策略进行参数化,所以我们通过几个梯度下降步骤来近似argmax。此外,如果需要,还可以使用熵正则化来防止策略变差。
-
具体来说,在每个迭代中,MBPO执行k-步推演,使用 从状态 开始,具有特定的推演策略 μ(a|s),将模型生成的数据 添加到 中,并使用从 中抽取的一批数据对策略进行优化,其中批次中的每个 数据点都从D中抽取,概率为 ,而 的概率为 。
COMBO的代码是在MOPO的基础上进行修改的, 但关键区别在于COMBO执行保守的策略评估,而不是使用基于不确定性的奖励惩罚。
根据MOPO, 我们使用神经网络表示概率动力学模型, 参数为θ, 产生下一个状态和奖励的高斯分布:。 该模型通过最大似然进行训练。
上面的Q函数学习到了真值下界,假设 Q函数是表格式的,由近似动态规划在第k次迭代中得到的 Q函数可以通过相对于 对 上式求导得到:
上式右边的惩罚项依赖于3个distributions。对于该式的第 k 次迭代, 我们进一步定义在 下的期望惩罚项为:
接下来, 我们将证明COMBO学习到的Q函数在初始状态分布和任何策略下都下界真 实Q函数。
我们还证明了COMBO学习到的渐进Q函数对于足够大的 ,于任何策略下都能学习到真值下界。采样误差和模型误差足够小时,一个小的β和一个合适的f也能保证这一点。
COMBO is Less Conservative Than CQL
COMBO不那么保守,因为它不会像CQL那样低估数据集中每个状态下的值函数,它甚至可能高估这些值。COMBO与之相比更能缩紧真值下界。
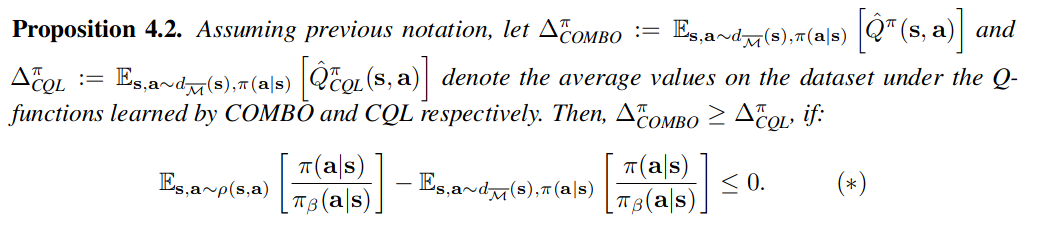
命题4.2表明,当 学习的策略 下的行动概率和行为策略 下的动作概率 在 从 得出的 (s,a)对(即使用策略 从模型中采样) 上,比来自数据集的状态 s 和来自策略的行动 a - 更接近时,COMBO将不如CQL保守。COMBO的目标函数只惩罚 下的Q值,在实践中, 预计主要由模型推演产生的分布外状态组成,而不惩罚从 得出的状态下的Q值。因此,表达式(*)可能是负的,使得COMBO不如CQL保守。
Safety Policy Improvement Guarantees
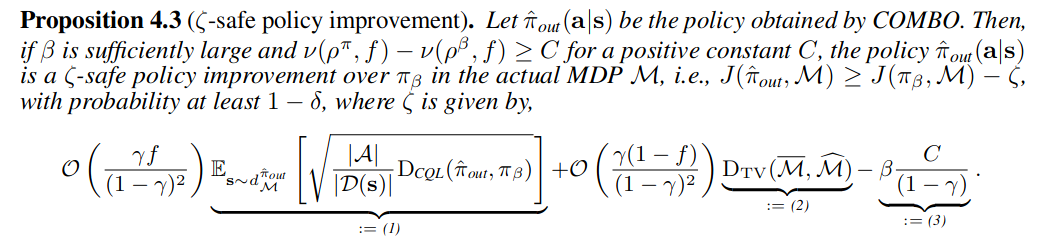
请注意,与 Kumar 等人在 [29] 中的命题 3.6 相反,我们的结果表明,当使用接近准确的模型来增加训练 Q 函数的数据时,抽样误差(公式(1))会减少(乘以分数f),同时它可以通过更多地依赖于无模型组件来避免模型为基础的方法的偏差。这使得 COMBO 能够通过适当选择分数 f 来达到无模型和模型为基础方法的最佳效果。
总结来说,通过适当的选择f ,该命题保证了在不要求一个有关不确定性估计的强假设情况下,安全地超过行为策略。
实验
-
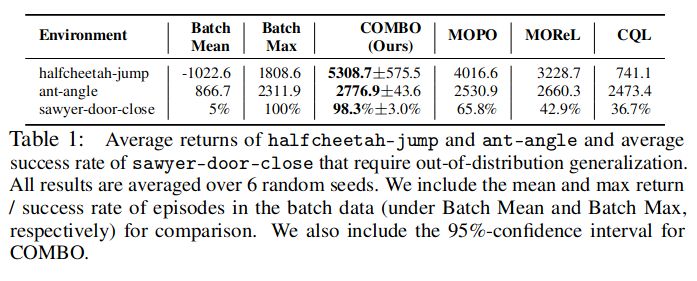
COMBO的泛化性能比较
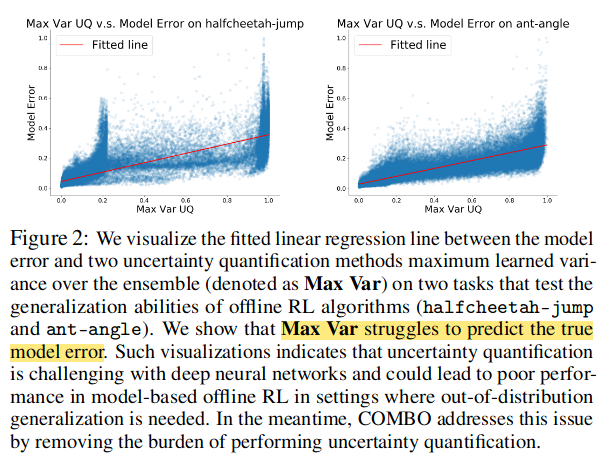
如图上所示,在这两个任务上, Max Var无法准确预测真实的模型误差,这表明离 线基于模型的方法所使用的不确定性估计不准确, 可能是导致其性能不佳的主要因素。 与 此同时,COMBO绕过了具有挑战性的不确定性定量问题,并在这些任务上取得了更好的性 能,表明该方法的有效性和鲁棒性。
-
COMBO如何在具有高维图像观察的任务中,与先前的工作进行比较?
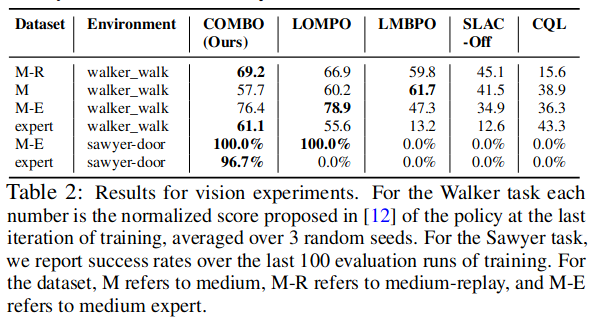
-
以标准的离线RL基准测试为依据,COMBO与之前离线无模型和基于模型的方法进行比较?
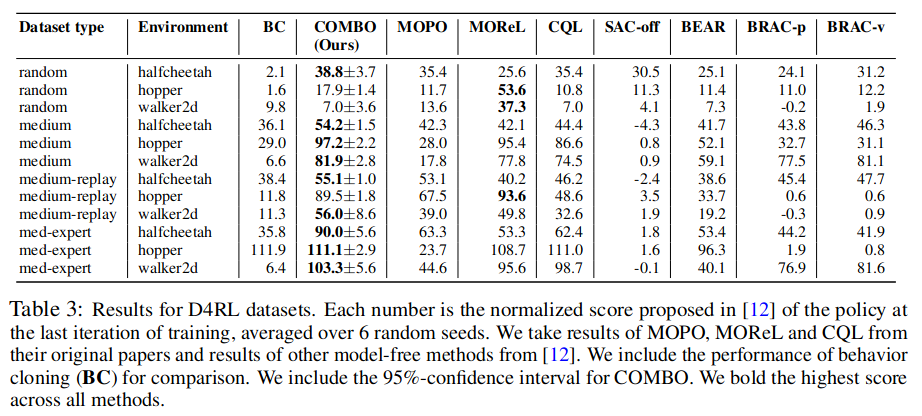
基于模型的离线方法通 常在通过广泛的策略收集的并且具有多样化的状态-动作分布的数据集上表现更好 (随机、 中等-replay数据集),而基于模型的无模型方法在具有狭窄分布的数据集上表现更好(中等、 中等-专家数据集)。然而,在这些结果中,COMBO相对于现有的基于模型的无模型方法和 基于模型的方法在各种数据集类型上表现良好,这表明COMBO对不同类型的数据集具有鲁 棒性。
之前的离线MBRL方法要么依赖于难以为深度网络模型实现的动态模型的不确定性量化, 要么像无模型算法一样直接将策略约束到行为策略上。相比之下,COMBO通过在模型推演过程中生 成的支持外状态中惩罚价值函数来保守地估计价值函数。这允许COMBO保留基于模型算法 的所有好处,如广泛的泛化能力,而无需显式政策正则化或不确定性量化的约束。
COMBO是一种基于模型的 离线RL算法, 它对评估超出支持状态-动作对的Q值进行惩罚。 特别地, COMBO消除了先 前基于模型的离线RL工作广泛使用的不确定性量化的需求,这在深度神经网络中可能具有 挑战性和不可靠性 。 理论上, 我们证明COMBO与之前的无模型离线RL方法相 比, 实现了较少保守的Q值, 并且保证了安全地策略改进 。 在我们的实证研究中, COMBO在需要适应未见行为的任务中实现了最好的泛化表现。此外,COMBO能够扩展到 视觉任务,并在视觉导航和机器人操控任务中表现出优于或相当的结果。最后,对于标准的D4RL基准测试,COMBO通常在不同数据集类型上相对于先前的方法表现良好