
Arxiv: MOReL
Abstract
MOReL是一个基于模型的离线RL算法框架。该框架包括两个步骤:(a)使用离线数据集学习悲观MDP(P-MDP);(b) 学习该P-MDP中的近似最优策略。学习的P-MDP具有这样的特性,即对于任何策略,实际环境中的性能都近似低于P-MDP中的性能。这使它能够作为策略评估和学习的良好替代品,并克服基于MBRL开发的常见缺陷。
Algorithmic Framework
| Symbol | Meaning |
|---|---|
| P | true transition dynamics |
| 学习的transitions | |
| HALT | a low reward absorbing state |
| USAD, | 未知检测器 |
| initial state distribution | |
| performance of π in . |

-
用离线数据集学习approximate dynamics model .
-
构造 USAD(Unknown state-action detector, 未知检测器):基于学习模型的不确定性来分类该状态动作对属于known或者unknown
-
构造 pessimistic MDP ,惩罚冒险进入未知(s,a)的策略:
上面增加了一种吸收态 HALT,我们将其引入到状态空间中。
P-MDP的作用:将状态-作用空间划分为已知和未知区域,并迫使从未知区域过渡到低回报吸收态(HALT)。
modified transition dynamics:
是Dirac-Delta函数,迫使MDP转移到该吸收态 HALT。这种强制的惩罚缓解了分布偏移和模型利用问题
modified reward:
对于未知的(s, a),使用-κ作为奖励,其他情况下,所有已知的状态动作都会获得与环境中相同的奖励。
-
MOReL中的最后一步是在上面定义的P-MDP中执行计划。为了简单起见,我们假设一个规划的oracle 可以在P-MDP中返回π-次最优策略。可以使用基于MPC[23,64]、基于搜索的规划[65,25]、动态规划[49,26]或策略优化[27,51,66,67]的许多算法来近似实现这一点。。
基于NPG算法。参考:四、自然梯度法 Natural Gradient
Theoretical Results
| Symbol | Define | Meaning |
|---|---|---|
| unknown states | ||
| hitting time,代表从状态s出发,执行动作a所需的最小步数 | ||
| $(1-\gamma)\sum_{t=0}^\infty\gamma^tP(s_t=s,a_t=a | s_0\sim\rho_0,\pi,\mathcal{M})$ | |
| ${(s,a) | (s,a,r,s^{\prime})\notin\mathcal{D}}\supseteq\mathcal{U}$ | |
| minimal sub-optimality | ||
| ensemble discrepancy | ||
| 不知道 |
证明部分主要证明了这几条:
-
P-MDP上的性能接近原始MDP,但更低 随着数据集大小的增加,和α将趋近于0,最终决定了次优的极限。
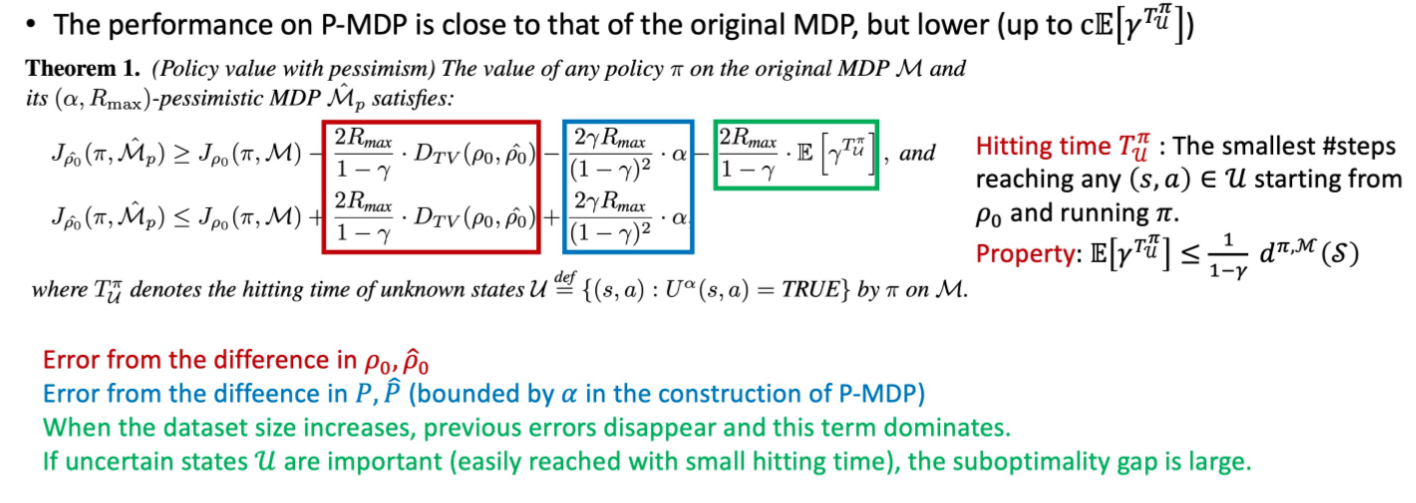
是 状态-动作访问分布,表示在一个策略下智能体和环境交互访问到的(s, a)的分布。1 − γ为归一化因子,好让所有状态的状态访问分布的合为一。
状态访问概率
-
MOReL学习的策略 比行为策略 更有可能得到改进。 这里描述了 和 / 的性能差异的上界。

这个界限由三个项组成:(i) 一个采样误差项 ϵn,它随着更大的数据集大小而减小,这是离线强化学习中典型的情况;(ii) 一个优化误差项 ϵπ,可以通过额外的计算来使其变小,以在学习的模型中找到最优策略;以及 (iii) 一个分布偏移项,它取决于离线数据集的覆盖范围和与最优策略的重叠程度。
之前的论文假设,其中 ( 是的子集),为离线数据集中没有出现的(s, a)的集合,并保证在这种假设下找到最佳策略。MOReL在三个方面显著改进了这些:i) 被一个更小的集合 取代,提高了泛化能力,ii)次最优性界被扩展到没有全支持覆盖的环境(full support coverage is not satisfied),即 ,以及iii)上的次最优性界是用未知状态命中时间(hitting time) 来表示的,这可能比仅依赖于的界要好得多。
-
这里描述了性能差异的下界。
仅使用 行为策略为 的数据集 学习的策略,其与最优策略的性能差异大于下列右式。

Practical Implementation Of MOReL
作者基于model-based NPG算法,提出了MOReL算法。其主要区别在于对离线环境的适配和使用学习的动力学模型集合(构建P-MDP)。
Dynamics model learning
用神经网络构造一个高斯分布作为 动力学模型 ,预测下一状态和奖励:
然后学习一个集成模型(ensemble of learned dynamics models)。
看不懂。
这种参数化确保了局部连续性,因为MLP只学习状态差异。MLP参数使用最大似然估计进行优化,并使用Adam进行小批量随机优化。
Unknown state-action detector (USAD)
为了将状态-动作空间划分为已知区域和未知区域,使用了不确定性量化(uncertainty quantification)。特别是,我们考虑使用模型集合的预测来跟踪不确定性的方法。是学习的模型,其中每个模型使用不同的权重初始化并且利用不同的小批量序列进行优化。
定义ensemble discrepancy:
所以实践中,USAD如下,threshold是一个可调的超参数:
Conclusions
We introduced MOReL, a new model-based framework for offline RL. MOReL incorporates both generalization and pessimism (or conservatism). This enables MOReL to perform policy improvement in known states that may not directly occur in the static offline dataset, but can nevertheless be predicted using the dataset by leveraging the power of generalization. At the same time, due to the use of pessimism, MOReL ensures that the agent does not drift to unknown states where the agent cannot predict accurately using the static dataset.
Theoretically, we obtain bounds on the suboptimality of MOReL which improve over those in prior work. We further showed that this suboptimality bound cannot be improved upon by any offline RL algorithm in the worst case.
我们介绍了MOReL,一种新的基于模型的离线强化学习框架。MOReL结合了泛化和悲观性(或保守性)。这使得MOReL能够在已知状态中进行策略改进,这些状态可能不直接出现在离线数据集中,但可以通过利用泛化的能力来进行预测。同时,由于使用了悲观性,MOReL确保了代理不会漂移到无法准确预测的未知状态。
理论上,我们得到了MOReL的次优性界限,这些界限优于先前的工作。我们进一步证明了在最坏情况下,任何离线强化学习算法都无法改进这个次优性界限。