
Arxiv: RAMBO-RL
我们将问题表述为与对抗性环境模型 进行的两玩家零和游戏。模型经过训练以最小化值函数,同时仍能准确预 测数据集中的转变,迫使策略在未涵盖在数据集中的区域保守行动。为了 近似解决这个两玩家游戏,我们在优化策略和对抗性地优化模型之间交替进行。
RAMBO通过以对抗性的方式修改学习的马尔可夫决策过程(MDP)模型的过渡动力学来结合保守性。我们将离线RL问题表述为对抗性环境的零和博弈。为了解决由此产生的最大化优化问题,我们以稳健对抗RL(RARL)的风格在优化代理和优化对手之间交替。
之前的离线MBRL方法是对执行环境中具有高不确定性的状态-动作对施加奖励惩罚。然而,这需要显式不确定性估计,神经网络模型的不确定性估计可能是不可靠的。COMBO提出了一种离线基于模型的RL方法,该方法不需要不确定性估计。
- 通过将无模型技术适应于常规监督学习的MDP的最大似然估计(MLE)来避免在线模型基离线RL中的不确定性估计需求。
- 通过提出一种新的RARL公式,将鲁棒对抗性RL方法应用于基于模型的离线RL,其中,我们没有定义和训练一种对抗性策略,而是直接修改MDP模型来达到对抗的效果。
因为在离线设置中对学到的模型进行朴素策略优化可能导致 模型滥用。为了解决这个问题,提出了一种强制保守性的新方法,通过对 的转移函数进行对抗性修改来实施。
算法

生成合成数据,类似MBPO在 中从状态 开始执行 k-步外推, 并将其添加到 。
训练策略,我们从 中抽取小批量数据,其中每个数据点以 概率 f 从真实数据 D 中抽样,并以概率 从 中抽样。
鲁棒对抗强化学习(RARL):策略 与对抗政策 的二人零和博弈来解决RL环境中寻找稳健代理策略 π
RARL 算法交替应用随机梯度上升步骤来增加期望值,并应用随机梯度下降步骤来降低期望值。
RAMBO遵循了 RARL 的交替更新代理和对抗者的范式,并将其适应于基于模型的离线设置。我们不是定义单独的对抗者策略,而是将模型本身视为要进行对抗性训练的策略。我们交替优化代理策略以增加期望值,以及通过对抗性地优化模型 来减少期望值。

因此,在方程3中定义的集合包含了类似于 状态-动作对下最大似然估计的MDP。 然而,由于方程3中的期待是在 D 下取的,所以对于 在状态-动作空间未覆盖的区域没有限制。问题1考虑了最坏情况下的过渡动力学,而由MOPO和MOReL构建的悲观MDP仅通过对具有高不确定性的状态-动作对应用奖惩来修改奖励函数。
策略性能保证理论分析
下面的理论分析表明,解决问题1输出的策略很有可能与数据集覆盖的状态-动作分布的任何策略一样好。

如果我们通过求解问题1得到一个策略,那么该策略的性能差距相对于具有数据集覆盖的状态-动作分布的任何其他策略 是有界的。此外,如命题 1 所陈述的,在问题 1 定义的集合中,最坏情况下的模型下的值函数是真实环境中的值函数的下限。
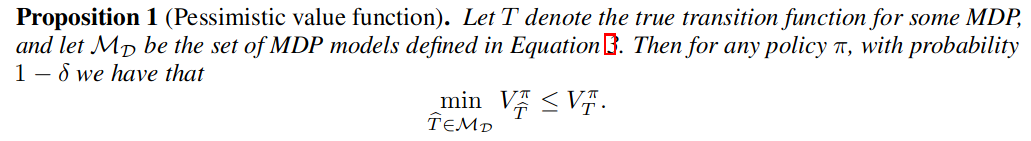
命题 1表明,我们可以期望任何在真实 MDP 中的策略的性能至少与问题1定义的最坏情况模型中的值一样好。
计算用于对抗性训练模型的梯度
我们提出了一种基于策略梯度的对抗性地优化模型。通常, 策略梯度算法用于修改在每个状态下由策略采取的动作的概率分布。 与之不同, 我们提出的更新修改 了MDP模型中后继状态和奖励的概率。
为了通过梯度下降近似地找到问题1所要求的 ,我们希望计算模型参数的梯度,该梯度降低了模型内策略的值,即 。

模型梯度与标准策略梯度的不同之处在于
- 它用于更新模型中后继状态的似然性, 而不 是策略中的动作
- 优势项将接收奖励r并转移到与状态动作 对(s, a)的期望值进行比较。
这样每次更新模型,使得在model给出的 准确的同时尽量使得当前V值尽量小。这样使策略和模型形成对抗的关系.
如何确保模型保持在 Problem 1中定义的约束集内
如果我们仅使用方程5更新模型, 这将允许模型被任意修改, 从而减小模型中的价值函 数。 然而, 由方程3给出的一组可能的马尔可夫决策过程状态表示, 对于数据集D, 模 型 应该接近最大似然估计 。
如果直接使用(5)更新模型,这会使得模型的更新方向不可控,可能减小模型中的价值函数,使得与MLE的更新相违背,故在原始问题的基础上增加约束:
对上式引入拉格朗日乘子变为无约束优化问题。然后本文实际中发现,固定权重参数就能够取得很好的效果。为了简化学习率的调整,将权重常数应用于值函数项而不是模型项,因为在缩放因子的情况下是等效的,则有
为了使算法高效且易于实现。 因此, 我们不按照公式 所规定的最小化模型和MLE模型之间的TV距离,而是直接优化标准的MLE损失。得到了最终的损失函数:
这样, 上式的模型的损失函数就这样简单地将对抗项添加到标准的最大似然损失中。 通过最小化该损失函数,模型被训练为 a)优化数据集中的转移函数,b)降低策略的价值函数。λ决定了这两个目标之间的权衡。 选择一个较小的λ可以确保了在 D 中的转移函数中, 最大似然项占主导地位,从而确保模型能够准确地拟合数据集。因为最大似然项只在D上计算,所以对抗项将在数据集之外占据主导地位,这意味着模型在数据集之外的转移函数中被修改为对抗性的。
上述过程是:从offline dataset中采样一个mini-batch衡量MLE,然后使用model-gradient计算第一项的梯度(值函数项的梯度)。model gradient的计算需要在当前模型和当前策略下进行计算(transitions必须在当前策略和模型下进行采样),此,为了估计模型梯度项 model gradient,需要使用当前策略在 中生成一个mini-batch
上面的损失函数包含两个可能在不同域之间具有不同大小的项,为了更容易地在不同的域中调整对抗性损失权重λ,需要在不同域中执行归一化过程。优势函数应该根据每个小批量的均值和标准差对优势项进行归一化。